Co-Pilots, Retrieval Augmented Generation, and Security
This week I’ve been testing setting up a local LLM using Retrieval Augmented Generation. RAG is a way to give generative AI data that it didn’t have when it was trained. The model provides semantic searching on unstructured data to be able to make use of all the files that sit on file systems like SharePoint. This is how some co-pilots work behind the scenes, using RAG with pre-trained LLMs.
Semantic searching is a huge improvement on the current keyword searching. With the current keyword-based approach, any search is pattern matched against the search terms. Your results will be a list of anything that contains the search term, without any understanding of the context in which it is used. Semantic search on the other hand, ‘understands’ the context of the question and can return a much more nuanced set of results, or summaries of the results so that you can see quickly if it is what you are looking for.
The value proposition for this use case is quite clear. If we can leverage the data we have in documents, spreadsheets and presentations with simple queries and summary information, we can become more productive in the workplace. Imagine how much work is re-done, time and time again, just because employees simply aren’t aware of what has been done before.
Searching file systems is cumbersome and time consuming. It usually involves a data trawl to go through the results and find what you are looking for. Imagine if you could ask a direct question, “Have we got experience of delivering widgets in the EMEA market after 2022, and have we had any issues with those supply chains?” Imagine then, that it understands the context of the question and summarises the documents it gets back into one-hundred-word answers. That is what generative AI is good at. GenAI allows semantic searching and summarisation of a variety of information sources (flat files, databases, etc.) and file types. This could save people time and reduce rework, a form of waste (which in my book Designed4Devops, I advocate removing!).
Security Domains
In the current models of enterprise IT, we create security domains. We use techniques like least privilege, role-based access control, and need-to-know. We layer these techniques to create security domains around data so that only the people that should have access to the data do so.
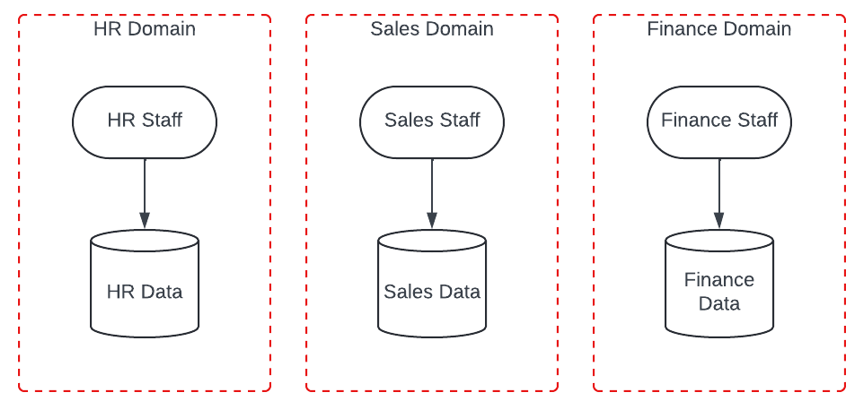
Gen AI with RAG Architecture
One of the typical deployment architectures for co-pilots and RAG, is to use an off-the-shelf model such as GPT, Llama, or Gemini, and give them access to embeddings of your data. The architectures often look like this:
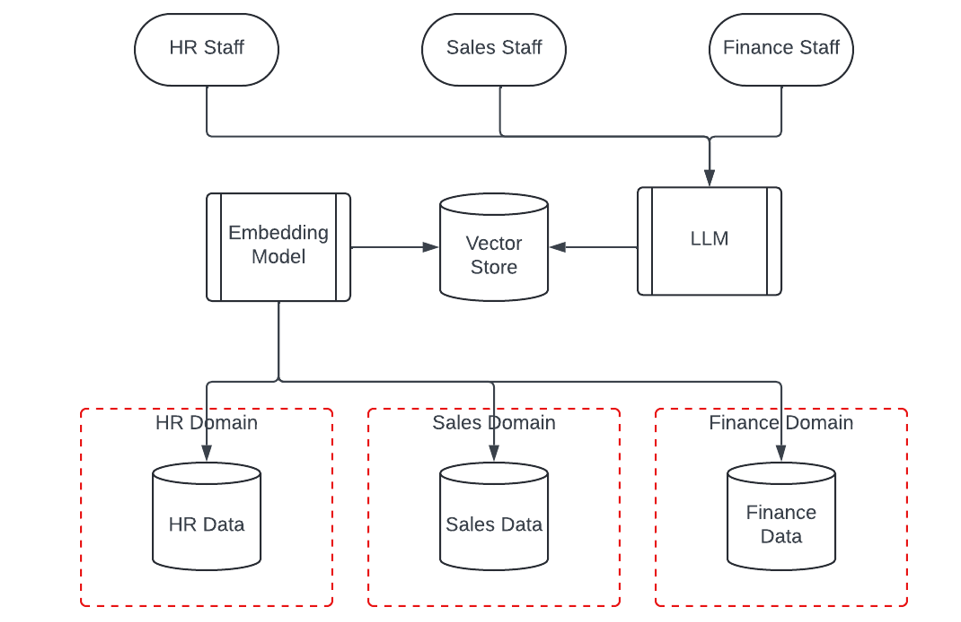
It’s clear that in this model we have created a security issue. We have breached the domains by creating a shared vector store that contains embeddings from the HR, Sales and Finance data. All three user domains can query the LLM for each other’s data.
Solving the problem with MLOps
We could create three deployments that maintain our security domains like this:
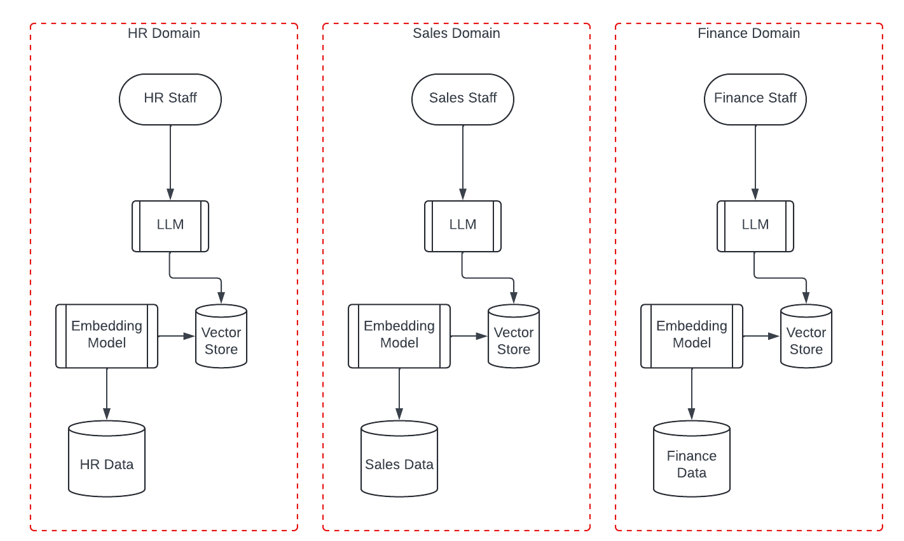
But there are issues with this pattern too:
- It doesn’t scale well. Whilst we have only three departments, this might work fine. But in larger or more complex organisations there may be many more domains. Each inference deployment will need its own resources – CPU, Memory, and GPU. Costs will quickly rise.
- We lose the ability to gain efficiencies of combining data for a wider context.
We can address the first point using MLOps. This is the automation of cloud delivery using DevOps techniques such as Infrastructure-as-Code and continuous delivery tools. We can create inference environments on demand but persist the embeddings in vector stores. That would significantly reduce our costs as we can use inference instances during office hours and scale them on demand.
To solve the second issue requires a different architecture as we’ll see in the next section.
Solving the problem with filtering
If we combine the domains to surface cross-domain information, we need some way to filter the answers it gives so that sensitive data doesn’t leak into the wrong domains. These features are relatively new but available from hyperscale and specialist vendors.
It is wise to provide a defence-in-depth approach. Take precautions to ensure that only non-sensitive data enters the embedding model and then via this, the vector store. The vector store contains all the embeddings of any data we included, and this is what the language model will query.
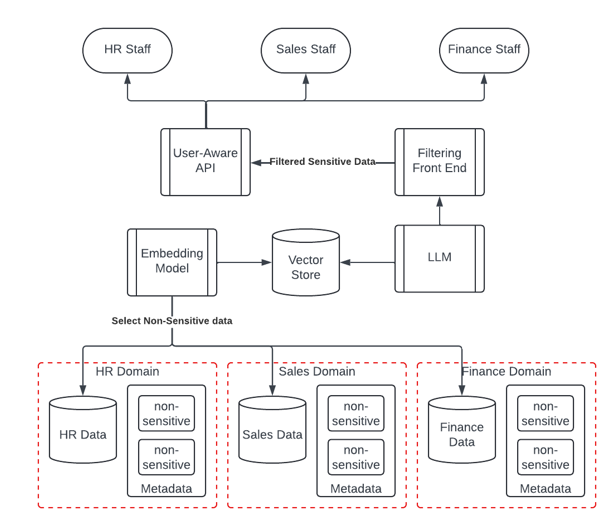
If we don’t allow sensitive data to enter the model environment to start with, we can be confident it won’t be returned to the users. When we prepare our data for inclusion into the embeddings, we should make sure that our metadata is consistent and of good quality. We then use the metadata to include or exclude data from the embeddings. This isn’t a new problem. Our data should be classified in terms of its sensitivity (public, sensitive, classified, secret), labelled, catalogued, and owned/curated.
We should also think about filtering at the front end. It is possible that by combining data we can create something sensitive from less sensitive sources. For instance, there might be enough data combined from HR and Finance to identify individuals which might contravene GDPR. We may also want to make sure that there’s no card or bank details, or that there is no inappropriate language in the response.
Be prepared
AI, Generative AI, machine learning, and all the other terms are about deriving value from data. To be able to deliver that value, we need to be on the front foot with our data management. If we assume that we will use generative AI (and given the amount of press coverage and investment that is a fair assumption), then we should start preparing our data now.
Start by cataloguing your data to know what data you have, who owns it, what it contains. Then start to prepare that data. Make sure it is classified for its sensitivity. Clean up the metadata and ensure that it is consistent and good quality. Have a standard for metadata descriptions.
Think about where your data is and how the models will access it. What format is the data in, databases, flat files, or something else? How will the models connect to it and consume it?
Lastly, map the security domains for your data. Will domains be breached or combined? How will data be filtered across those domains?
As ever, if you need help with any of these topics, feel free to get in touch on info@methods.co.uk.