Data is all you need
Data preparation is often overlooked by people wanting to work in AI. It’s not as glamourous as developing deep learning models and playing prototyping with the latest and greatest GPUs. But as we’ll see in this article, even small changes can make a big difference to the overall cost of your service.
An AI model requires resources to train, deploy, and infer. Cloud, where most of us will deploy our resources, charge by CPU/GPU/memory-hours. Using less CPU, GPU, and memory will cost less in the long run.
The theory
My expectation was that reducing the number of features in a data set would result in a smaller model. Less features should result in less cycles and lower memory consumption.
The test
I wanted something quick and easy to set up and that was easy to iterate changes and see the results instantly. I also wanted it to be cheap. Luckily Kaggle provides this capability for free! It provides access to a Jupyter Notebook environment on demand with access to time-restricted CPU/memory/GPU resources.
Jupyter is a Python runtime environment that allows you to develop models interactively and see the results. You can see my notebook on Kaggle and GitHub.
I chose the Kaggle competition for predicting who gets abducted by aliens off the Spaceship Titanic in 2912. It’s a logistic regression problem to categorise passengers into one of two categories, ‘transported off’ or ‘not transported off’. I chose this model as the data sample is small enough, repeatably iterate for free in Kaggle, and you can see results in real time.
I started by normalising the numerical data and then one hot encoding the categorical features. It created a sparse(ish) matrix of features. Using a Seaborn Heatmap, we can see how the features related to each other:
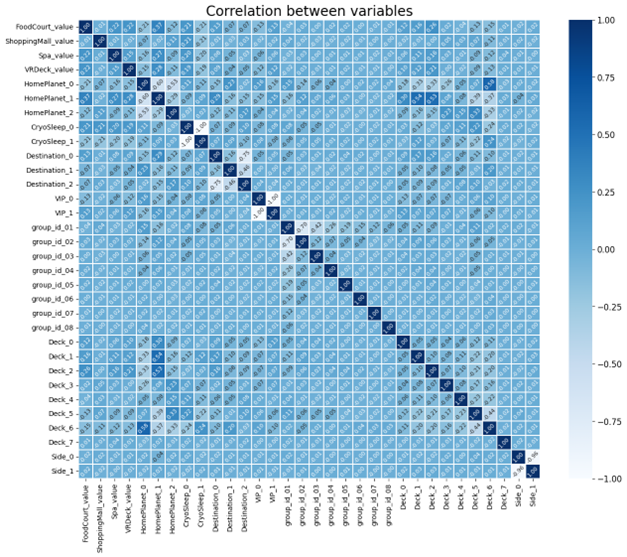
I ran several classifier models against this data set to record their accuracy and memory usage.
In the image you can see that several features don’t appear to have much correlation with the others, notably ‘group_id’ and ‘Side’. I then pruned the features from the model to get a smaller matrix:
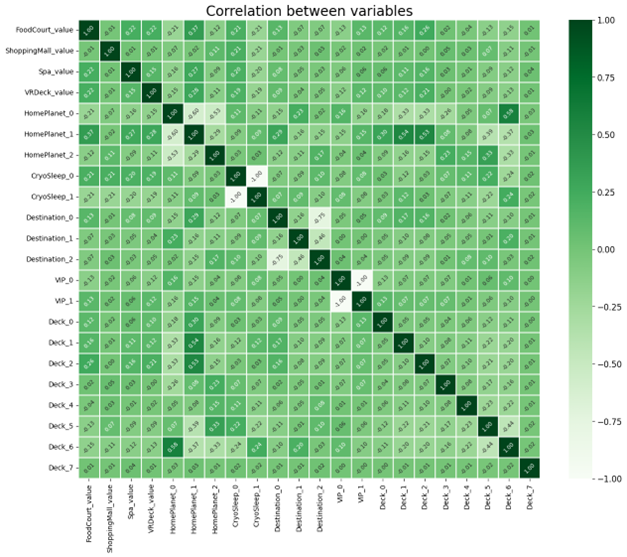
This diagram shows that the remaining features have a closer correlation. Most of these features have at least one darker or lighter patch. I ran the same set of models and again recorded their memory usage and accuracy.
The results
The table shows my results, some of which are surprising.
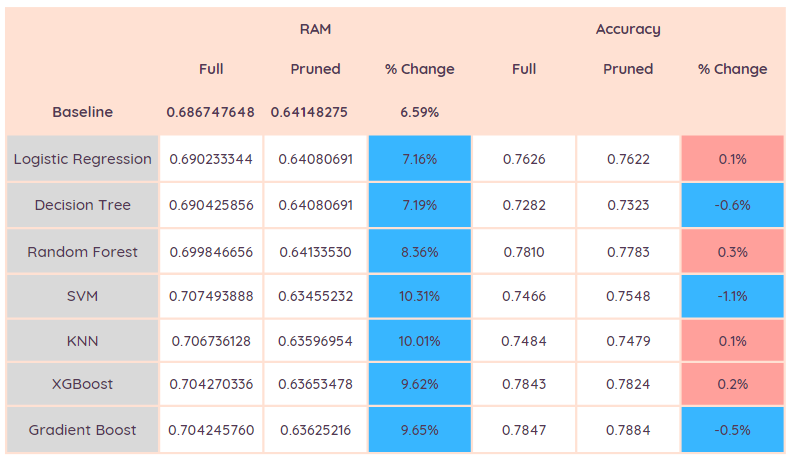
All classifier models used approximately 7-10% less memory (blue shows improvement) with the pruned model as expected. Unexpectedly, some models showed an improved accuracy with the pruned model! I’m going to investigate why this might be for a future blog.
Conclusion
With the abundance of cloud resources (compute, memory, storage, networking) and someone else paying the bill, it can tempt us to keep all the data and to throw all of it at our model. I hope this simple test gives you cause to pause.
The larger our model is, the more it will cost in hosting and the more electricity it will consume. We are wasting energy and money as well as driving up CO2 with our behaviour. These models will eventually become part of an application, probably running in containers. They could be duplicated 10/100/1000 times at peak times. If we spend a bit more time at the data preparation stage, we can not only be more efficient, but also improve the accuracy of our models.
Takeaway
Here are some points to consider:
- Preparing data effectively will create a more efficient model and cost less to run.
- Preparing data effectively can produce a more accurate model.
- Don’t jump for neural networks, running on the fastest GPUs. These classifier models all produced ~80% accuracy running on a CPU alone – no GPU (GPUs are expensive)! They could be much more expensive to run in production for inference. Look to the fastest and simplest solutions first.
If you need help with data preparation or AI implementation in your organisation, Methods can help you with the journey at every step of the way.